Building End to End COVID-19 Forecast Model using Azure ML
A few months before, we would have never thought how the entire would change due to the pandemic caused by a virus so-called COVID19 a.k.a Coronavirus. It has changed how the entire world works right now and we must salute to the people working in the frontline to prevent, cure us of this deadly virus.
As a Data & Cloud Enthusiast, I wanted to contribute my purpose in these times of dire situation and most importantly to empower people with AI/ML knowledge to contribute. I hope this tutorial article would serve one of its purposes. I have tried my best to simplify the process that you can build your own model at the end of this article. All you need to know is the basics of Python Programming to get started!
The website I had created is https://newcovid.herokuapp.com to visualize and get real-time information about COVID-19 status worldwide, India (State and District wise) and most importantly, the forecast of COVID-19 cases in India for next 7 days.
On you mark….
Step 1: Get your Azure Account
First thing first, we need to get an Azure Account to get started. If you have one, that’s well and good. If not, don’t worry, Microsoft is giving a free trial to access Azure Cloud. Register and sign up here: https://azure.microsoft.com/free
Step 2: Setting up the Workspace
We need to create a workspace for our project. Workspaces are Azure resources, and as such, they are defined within a resource group in an Azure subscription, along with other related Azure resources that are required to support the workspace.
In your Azure portal homepage, click “Create a Resource”. Since we are going to do many ML tasks, now select “AI + Machine Learning” under Azure Marketplace column. Select the first option “Machine learning”. Now create a workspace by filling up the following details. Enter the details as shown the image. You are free to use any name for the Resource Group, Workspace. Select the appropriate subscription (Free trial if you are using one). Click “Review and Create once it is done”.

Since we need a compute instance to run the entire ML tasks, let’s create one. Go to ml.azure.com. On the left side, click “Compute”. Under Computer Instances, click New. Give a name for your Compute Instance and select Virtual Machine type as “STANDARD_DS3_V2”. Wait a minute or two for your VM to spin up.

Click “Jupyter” and that will take to Jupyter Notebooks.
Create a new folder by clicking “New” on the right side. Navigate to the folder and then create new “Python 3.6 Azure ML”. Open the .ipynb notebook file you had just created.
Step 3: Creating an experiment
We need to connect our load our workspace and set up a new experiment, say “covid_exp”. This can be done as shown below
Step 4: Creating a Pipeline script file
We are going to create a script file which will be the input to the ML Pipelines. ( Don’t worry, we will come to back to Pipelines in the later section of the article)
The following lines of codes under this step must be executed in single notebook cell.
The script is going to perform the following actions under the run context of our “covid_exp” experiment.
- Import the COVID-19 Indian Data.
- Train the forecasting model
- Upload the forecast data to Azure Storage.
Import the COVID-19 Indian Data
First, we will create a new python script file called prediction.py and import all necessary libraries. You can run these lines of code in our .ipynb Python Notebook we are working on.
We need to define the run context for the experiment, followed by importing the COVID-19 Indian data from https://api.covid19india.org/data.json
Load the Time series data in Pandas data frame. We will be working on the daily number of cases of confirmed, recovered and deaths. Split the data as Train and test dataset with 0.75 ratios.
Train the forecasting model
We can infer that this is a typical Time Series Forecast Problem BUT it is not. To model the spread(infection) and control(recovered) of infectious diseases, a mathematical model such as SIR (Susceptible-Infected- Recovered) Model. This section of the article is the playground of Data Scientists, you can come up with the models for this data.
To know more about SIR Model and its implementation, refer: https://www.kaggle.com/lisphilar/covid-19-data-with-sir-model
Write the forecast data to a local file called covid_pred.txt
Upload the forecast data to Azure Storage
The forecast data is available in covid_pred.txt must be uploaded to Azure Storage as a blob. This blob can we be accessed by Anonymous request to use the forecast data. The following steps need to be done to create a storage account and upload the blob.
- Go to Azure Portal homepage and click “Storage Account”. Click “Add”. Enter the required details to create an account. Be sure to mention the same Resource Group name.
- We need to create a container to store our file. Click the storage account we created and then click “Containers”.
- Create a new Container named “covidprediction”. Set the access level to “Blob”
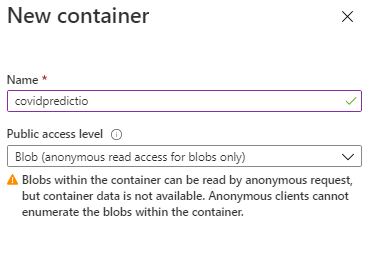
4. Once the container is created, navigate inside the container. The Container is going to hold the uploaded forecast data as a blob. Click “Upload” and select an empty text file. Give a name for the blob .
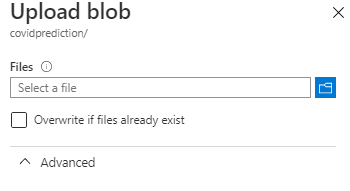
5. Click “…” of the created blob and select “Generate SAS Token”. Leave the settings as follows. Copy the Blob URL (you need it later).

6. Coming back to our pipelinescript.ipynb. As our last step of our Python script file prediction.py is to upload the content of covid_pred.txt to the blob we had just created using SAS token. Complete the run of the experiment by run.complete()
Step 5 Creating and scheduling the Pipeline
A Pipeline object contains an ordered sequence of one or more PipelineStep objects. The pipeline is going to execute the script prediction.py
Allocate the compute cluster for the pipeline to be executed. You can use the same compute for this.
Create a Conda Environment for the pipeline by including the necessary libraries for execution. Name the environment, say “covid_env”
Now we need to define the pipeline Object which consists of the Pipeline step which is going to execute prediction.py on compute cluster.
Now the pipeline is ready and we need to execute the pipeline and publish it as “covid-pipeline”.
We can schedule the pipeline to be run at the time specified by us. For our problem statement, the SIR model will predict the new forecast for next 7 days every day. So the pipeline needs to be scheduled to run once a day using the pipeline id generated in above code.
Step 6: RUN IT ALLLLLLLLLL!
Now execute all the cells in pipelinescript.ipynb. You can view the execution details in the output cell. Once the execution is over, we can notice two results
- Blob file contains the forecast data
- The Pipeline is scheduled to be run every day.
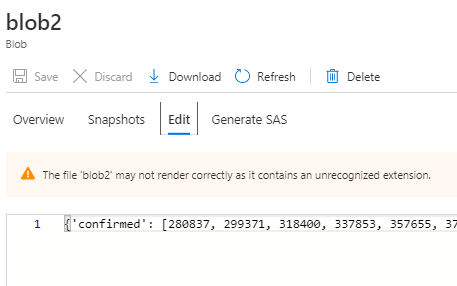
The blob forecast data may vary according to your model.
Step 7: Access forecast data
Now we need to make the blob to be accessible by applications. This can be done by an HTTP request. To make sure the data access safe, we need to modify CORS policy such that our application can access the blob.
Go to Storage Account in your Azure Portal → Click the account → Under Settings click CORS → Update the URL and necessary information as below.

As my website wants to access the blob, I had allowed the ‘GET’ method.
The blob now can be accessed with the SAS Blob URL we had generated in Step 4.
Step 8: Visualization of Output
The plot of trends of daily confirmed cases + forecast and Daily recovered + forecast can be seen in the below two graphs hosted in the website


Voila! Congratulations on creating an end to end ML model for COVID-19 forecast system using Azure ML. If you loved the article/tutorial, give claps, share to other devs as well.
Feel free to reach out to me regarding queries, suggestions, critics, appreciation, feedback through Email: vivekraja98@gmail.com, LinkedIn.
References/ Resources:
- https://www.who.int/emergencies/diseases/novel-coronavirus-2019
- https://docs.microsoft.com/en-us/learn/paths/build-ai-solutions-with-azure-ml-service/
- https://azure.microsoft.com/free
- https://ml.azure.com/
- https://en.wikipedia.org/wiki/Compartmental_models_in_epidemiology
- https://www.kaggle.com/lisphilar/covid-19-data-with-sir-model
- https://docs.microsoft.com/en-us/azure/storage/common/storage-sas-overview
- https://docs.microsoft.com/en-us/rest/api/storageservices/cross-origin-resource-sharing--cors--support-for-the-azure-storage-services
- https://www.highcharts.com/
- https://www.djangoproject.com/
- Tons of Stackoverflow queries
